
kaiyun欧洲杯app(官方)官方网站·IOS/安卓通用版/手机APP下载我之前也跟我的导师研究过-kaiyun欧洲杯app(官方)官方网站·IOS/安卓通用版/手机APP下载
文|硅谷101kaiyun欧洲杯app(官方)官方网站·IOS/安卓通用版/手机APP下载
跟着近两年来生成式AI本事的进步与普及,使用大模子来生成内容也已缓缓成为浅近东谈主生存的一部分。这个经由看起来似乎很大意:当咱们输入一个领导,大模子就平直能为咱们输出谜底。关联词在这背后,模子里面的使命旨趣和模子方案经由却并莫得东谈主知谈,这即是广为东谈主知的“机器学习黑盒”。
因为黑盒模子所存在的不可解释性,AI的安全问题也一直备受质疑。于是科学家们启动试图去绽开大模子的黑盒子,业内称之为“白盒研究”。一方面,白盒模子的研究能匡助东谈主们领会黑盒模子,从而对大模子进行优化和遵守的普及。另一方面,白盒研究的主见是要把AI这一工程性学科推向科学。
这次,咱们邀请到了加州大学戴维斯分校电子与计较机工程系助理栽培陈羽北,他的研究内容就与“白盒模子”研究。此外,他亦然图灵奖获取者、Meta首席科学家Yann LeCun的博士后。本期节目中,他和咱们聊了聊白盒模子的最新研究阐述,同期也向咱们共享了他所熟识的这位经验过AI行业起升沉伏、却依然地谈专注的科学家Yann LeCun。
以下是部分访谈精选
01东谈主脑与大模子
《硅谷101》:可以先绵薄先容一下你正在作念的“白盒模子”研究吗?在你的研究经由中有莫得发现如何能去解释 GPT 的输入输出问题?
陈羽北:这个标的其实一个比较大的主见便是深度学习从一门纯训戒性学科向一个科学学科来鼓舞,或者说把工程变成科学,因为目前工程发展得比较快但科学相对舒适。以前有一个模子叫作念词的镶嵌(embedding),它可以学到讲话的一些表征。
群众那时其实就有一个疑问,咱们作念任务的性能变好了,然则究竟是什么导致这个性能变好了?是以咱们那时作念过一个相等早期的使命,便是尝试绽开词汇的这些暗示。当你把它绽开的时候,就会发现一些很挑升想的阵势。
比如说苹果这个词,你可以找到里面的一些元真谛,比如其中的一个真谛可能便是代表生果,另外一个真谛代表甜点,再往下挖会找到有本事和居品的真谛,自然指的是苹果公司的居品。是以你就会发现顺着一个词你能找到这些元真谛,接着你就可以把这样的门径延长到大讲话模子里。
也便是说,当咱们学完一个大讲话模子以后,可以在模子里面去寻找它里面所带有的一些元真谛,然后尝试去绽开。你会发现一个大讲话模子,它其实有好多层。
在低级层里,它会出现一个阵势叫“词语的消歧”。比如像在英文里面有个词叫作念“left”,这个词它既有向左转的真谛,也有离开的往常式的真谛,那么它具体的真谛则要取决于语境前后的崎岖文,是以大讲话模子在初期的几层里就完成了词语的消歧。
而在中期你会发现又有一些新的真谛产生。那时咱们认为一个很好玩的事叫作念“单元改革”,一朝要将公里变成英里、温度从华氏度变成摄氏度的时候就会被激活,这个真谛就会被绽开,你可以顺着这个路找到好多相似级别的这种元真谛。
你再往上走的时候甚而会发现这些元真谛中存在一种礼貌,这种礼貌便是当崎岖文里出现了一个近似的真谛时它就会被激活,你就可以用这样的相貌去绽开大讲话模子以及小讲话模子。自然这些想路也并不完全是新的,它在视觉模子里其实照旧有一段历史了,比如说从Matthew Zeiler启动就有一些类似探索。
《硅谷101》:顺着这个想路,是不是要是咱们知谈了它部分是怎么运作的,就可以从工程上对它有好多优化?
陈羽北:是的,这个是一个相等好的问题。我认为作念任何表面一个比较高的条款便是可以引导实践,是以在咱们那时作念讲话模子还有词汇表征的时候,那时也有的一个主见,便是当咱们领会以后,能不成反过来优化这些模子?其实是可以的。
举一个例子,要是你在大讲话模子里面找到的一个元真谛,当它看到某一种元真谛的时候就会激活,那这一个神经元就可以被看成一个判别器,你就可以用这个东西来作念一些任务。通过对这些元真谛的改变,来改革模子的偏见。
便是要是我能够发现它,那我可以诊治它。最近 Anthropic 他们便是作念了类似的一个使命,便是找到讲话模子里边可能存在的一些偏见,然后对它进行一些改变来使这个模子变得愈加的公和蔼安全。
《硅谷101》:我看到昨年 OpenAI 也有一项研究,便是用 GPT4 去解释 GPT2,看 GPT2到底是怎么使命的。比如说他们发现GPT 2的神经元在修起通盘跟好意思国历史1800年前后的事情时,第5行的第12个神经元会被激活,在修起华文的时候是第12行的第13个神经元被激活。
要是把它修起华文的这个神经元关闭的话,它对华文的领会技艺就会大幅的着落。但是越往后的神经元,比如当神经元到了2000排支配的时候那它通盘的实在度就照旧着落了好多。你有莫得留神到他们的这个研究?
卤鹅文化周的火爆并不是偶然。众所周知,卤鹅是潮汕百姓餐桌上不可或缺的硬菜,潮州卤鹅尤以磷溪卤鹅闻名。对于潮州人来说,它既是美味,也是乡愁,是很多人对于家乡的活态记忆。首届潮州(磷溪)卤鹅文化周以乡愁作为引擎,撬动产业、文旅等资源,凝聚起潮州人的情感认同,推动了乡愁文化和经济要素的双向激活。
肇庆四会举行“首届乡厨大赛暨万人品尝茶油鸡美食嘉年华”活动。 南方+ 施亮 拍摄

OpenAI的研究:让GPT4去解释GPT2的神经元
陈羽北:这篇著作我还没看过,不外这个门径它相等像是给大脑的神经元作念手术。格外于目前要是有一个神经的收集,这个收集是指从某种真谛真谛上能找到一个局部的存在而不是完全散布的,那么就可以对它进行一些操作。比如把某个神经元切掉了,那你就可以认为它某一块的技艺相对来讲就归天掉了。东谈主其实亦然一样的,比如一个患有癫痫的东谈主在作念完手术后可能会出现某些讲话的扼制,但并不太影响其他东谈主体功能,这从旨趣上看起来是相似的。
《硅谷101》:OpenAI、Anthropic他们目前都在研究大模子的可解释性,你的研究跟他们之间有什么区别吗?
陈羽北:白盒模子的研究是否将来能到手其实群众都不知谈,我之前也跟我的导师研究过,但群众一致的看法是说这件事值得尝试。要是咱们回到这一块的话,咱们的研究想作念的其实是想领会东谈主工智能,况兼通过咱们的领会重构它,进而从根底上来构建出一些不一样的东西。那么不雅测,也便是可解释性我认为只是一种技能。也便是说,绽开这种模子也好,我作念这些实验也好,对模子进行一些诊治也好,我认为这都是咱们在领会的经由中所尝试的一些技能,但是白盒模子实在伏击的照旧要回到这个信号自身。因为无论是东谈主脑也好,机器也好,它们的学习的骨子都因为信号。
咱们这个天下中存在一些结构,他们也要通过这些结构来进行学习,学的也恰是这些结构。那么咱们是否可以找到这些结构背后的礼貌,以及暗示他们的一些数学器具再把这些东西进行重组进而构建出来一个不一样的模子?要是这件事可以完成的话,我想就能带来对于提高咱们的系统的鲁棒性,或者安全性和实在度的一种期许。另外,它的遵守也会提高。这有点像是蒸汽机先出来之后才出现了热力学这种表面,从而相沿它从一门完全的工匠学科变成了一门科学。那么同理,今天咱们就好像是第一次在数据上有了蒸汽机,从以前不睬解咱们的数据,到目前终于可以启动作念出来一些 AI 的算法把数据中的礼貌给握出来。
《硅谷101》:是以它会更节能。
陈羽北:要说到节能,我可以举几个挑升想的例子。第一个点细目是节能,因为大脑它格外于一个20瓦功耗的一个灯泡,那目前的超等计较机它可能要高出百万瓦。
第二点是,要是咱们看自然界多样千般生物所进行演化,它的演化遵守其实吊问常高的。比如有一种特殊蜘蛛叫Jumping Spider,它唯有几百万个神经元,但它可以作念出相等复杂的三维的群线去捕捉它的猎物。
而我认为最挑升想的一件事儿是东谈主对于数据使用的遵守。Llama3目前的数据量概况照旧达到了13万亿个Token。但东谈主的一世当中到底能接管若干的数据呢?假定咱们每秒可以获取30帧图像,每天的获取时刻是12个小时,作念20年,那么咱们概况能得到100亿个token,翰墨能获取的亦然差未几一样,数据量比大模子小太多了。那么问题来了,东谈主究竟是如何通过如斯少的一个数据量来获取如斯强的一个泛化技艺的呢?这便是东谈主脑在遵守层面让我认为很神奇的一丝。
《硅谷101》:去揭开大模子是怎么运作的和跟揭开东谈主脑是怎么运作的哪个更难?我听起来都很难。
陈羽北:这两者各有各的难法,但在门径上是相似的。无论是东谈主脑照旧大讲话模子,咱们都是尝试去不雅测它,看它对什么产生了反应。
这个门径其实从上个世纪80年代获取诺贝尔生理学奖得主David Hubel和Torsten Weisel对于视觉皮层的研究中就能看到。他们找到了一种Simple Cell,尝试研究东谈主看到什么东西的时候这些神经元它会产生冲动,分析看不同的东西时候神经元不同的反应气象,比如什么时候完全不反应,什么时候又很振作,接着他们就找到了神经元的 Receptive field。
而咱们今天研究大讲话模子其实亦然相似的,找不同的输入,然后领会模子里面的哪些神经元是对哪些输入感兴味的。不外它们仍然有区别。
第一个区别是,无论是通过插电极照旧脑机接口等门径对东谈主脑进行不雅测,都有好多的限定,但大讲话模子有一个自然的刚正便是不雅测技能不再受限了,要是你有更好的门径,你就可以经久去分析,甚而你还可以通过一些微分的门径对模子进一步分析。
但是它的波折是,大模子的技艺还远远不足大脑,尤其是大讲话模子,因为它只从讲话里面来学习这个天下,是以它的对天下是领会是不好意思满的,就好像一个东谈主他莫得了其他的感官唯有讲话。
比拟之下,大脑能处理更多维的信号,感官吊问常丰富的。无意候咱们会想一个问题,便是讲话是否是完备的?要是莫得其他感官的相沿的话,讲话里边是不是通盘的宗旨都可以孤立存在,照旧一定需要其他感官看成相沿,才有可能已毕实在的领会。
举个例子,“雪柜”这个东西要是不和现实天下的冷热感受关联,只是描摹它有门等这种统计特征,是不是这种描摹便是不完备的。
《硅谷101》:是以其实目前大模子跟大脑比拟,它照旧欠缺相等多的。但是因为咱们可以把它停止来研究,是以你认为它照旧会比揭开大脑的玄妙的这个贪念略微更进一步。
陈羽北:领会大讲话模子它的难度在于你不雅测的技能多,对它领会也能更多。比如有两台机器,一台机器完全可不雅测,一台机器部分可不雅测,那从直观上来讲是完全可不雅测的这台机器就更容易被领会。自然它有一些技艺是这台机器莫得,是以不成取代对东谈主脑的一些领会。
《硅谷101》:我跟听众也补充先容一下,羽北之前是学神经科学的。那你认为对你的学科布景对目前来作念 AI 标的的研究有什么匡助吗?会不会有一些跨学科的可以相互模仿的研究门径?
陈羽北:我其实也不是专科学计较神经科学的。我本科是在清华的电子系,在伯克利是电子工程计较机系,但那时我所在的研究所是一个神经科学的一个研究所,是以我导师是计较神经科学的大家。
对于刚才阿谁问题,我认为神经科学的学习对我来讲的匡助粗俗是一种启发。因为当你知谈自然界的这些系统,知谈它们可以作念到什么的时候,你可能就会有不一样的想法,会从头看待目前的问题。
举个例子,一张图片它是一个二维输入信号,它的像素有横向的、纵向的,然后它变成一个网格。但东谈主眼视网膜并不长这样。率先它是种领有不同感知的感受器,这个感受器是以相等密集但又不吊问常礼貌的相貌排布的,它中间相等的精良,向双方的时候会变得寥落。当你面对这样一个输入信号的时候,率先咱们习以为常的这些东西就都失效了,因为连卷积在这里都莫得界说。是以当看到生物系统里的这个情况,就会从头去想咱们所谓的这些卷积到底从何而来。
《硅谷101》:是以你会从头去想门径是不是对的?是不是一定要以这种相貌来已毕?
陈羽北:是的。便是假定有一天你醒来,通盘的神经元都打乱了,那你还能再去领会这个天下吗?因为你看到的照旧不再是一张图片了,你也不成再用卷积神经收集来作念这件事情了,你需要什么样的门径?
诚然咱们还没完全管理这个问题,其实目前也照旧走了一步。诚然我的通盘的神经元都打乱了,便是咱们的感受器图像里边的这些像素打乱了,然则相邻的这些像素它们有一些关系。比如咱们看图像时我会发现要是一个像素是红的,那周围的像素也更可能是红的,那么通过这种关系你就可以去让这些像素他们从头去找一又友,然后就可以把相似的像素自组织成一些关系。
然后这个时候再加上大讲话模子里 Transformer 这样的结构,就可以从头的对这种图像作念出一个暗示,而且这个暗示的性能还可以。这个便是一个完全从自然的启发去从头扫视咱们目前的工程上的一些作念法、然后提议一些不同门径的例子。
《硅谷101》:嗅觉研究AI大模子和东谈主脑神经科学照旧有好多相似之处的。会有神经科学家从他们的角度来跟你们产生跨边界的研究配合吗?
陈羽北:其实有好多的神经科学家、统计学家以及数学家他们想要领会自然信号中的一些结构,同期也会关心大脑中的神经元它们是如何运作的,然后把这两者市欢在沿途,尝试去提议一些极简的对于信号的一些暗示。
举一个例子,在大脑里面你会发现存一个阵势,便是神经元诚然好多,但团结时刻在使命的这些神经元其实吊问常的寥落。比如有100 万个神经元,可能就唯有几千个在使命。
证据这个,早年神经科学边界就提议来一个寥落编码的门径,也便是在这种高位信号中,能不成找出一些寥落的低维暗示?从这样的想路登程所构建出来算法,就和你在大脑里面不雅测到的这些神经元暗示相等附近,是以这个是早期计较神经科学无监督的一个到手。
到今天来讲的话,咱们通盘的这一块研究边界有个名字叫作念自然统计信号的研究(Natural Signal Statistics),它的主见便是揭示信号背后的一些基本结构,但和大模子比拟,和白盒模子这类神经科学市欢的研究它的发展其实相对来讲慢一些的。我其实认为一方面可能是因为问题复杂,但另一方面亦然因为干涉这个标的的东谈主比较少。
02黑盒模子的“弯谈超车”
《硅谷101》:绵薄来说便是目前研究白盒模子的东谈主太少了。但是在大模子出现以前,传统的机器学习是不是也属于白盒模子研究的边界?
陈羽北:我认为这个说法可以认为是对的,以前的这些机器学习的模子相对绵薄,相对来讲都可以领会。
《硅谷101》:那为什么目前通盘的黑盒模子的研究阐述对白盒模子已毕了弯谈超车,速率可以快这样多?
陈羽北:这个问题问出来咱们就先会是弥留一下,然后再修起。
《硅谷101》:为什么关键张?
陈羽北:因为这个问题很敏感,其实是在问是不是白盒模子、或者说可领会的这条旅途咱们就应该覆没了。从咱们这个期间启动,是不是在AI边界咱们照旧不再研究科学了,以后皆备变成一个训戒性学科?但我认为还不是。回到你刚才的这个问题,这个经由中到底发生了什么?率先一丝便是黑盒模子的背负少。你既要这个门径可以使命又要这个门径可以解释的话条款就太多,那黑盒模子就覆没了一条让他先可以使命。
第二是相对来讲被群众所疏远的原因,便是数据的逆势增长,或者说是规模扩大。
Richard Sutton之前写了一篇博客里面曾提到,在往常的 20 年里面有一个一直莫得被冲突的东西,便是当咱们有更多的数据、更多的计较,应该找到比较能够实在推广的算法去把通盘的数据的这种礼貌找进来。我认为这个是黑盒模子里,或者说是咱们目前的训戒性的阐述里很伏击的一条。
便是说当咱们有更大的数据、更好的数据,更多的计较、更大的模子,然后就能学得更多。但是咱们回到这个问题的话,便是白盒模子里群众有一个追求,是说模子自身要具有残害性。
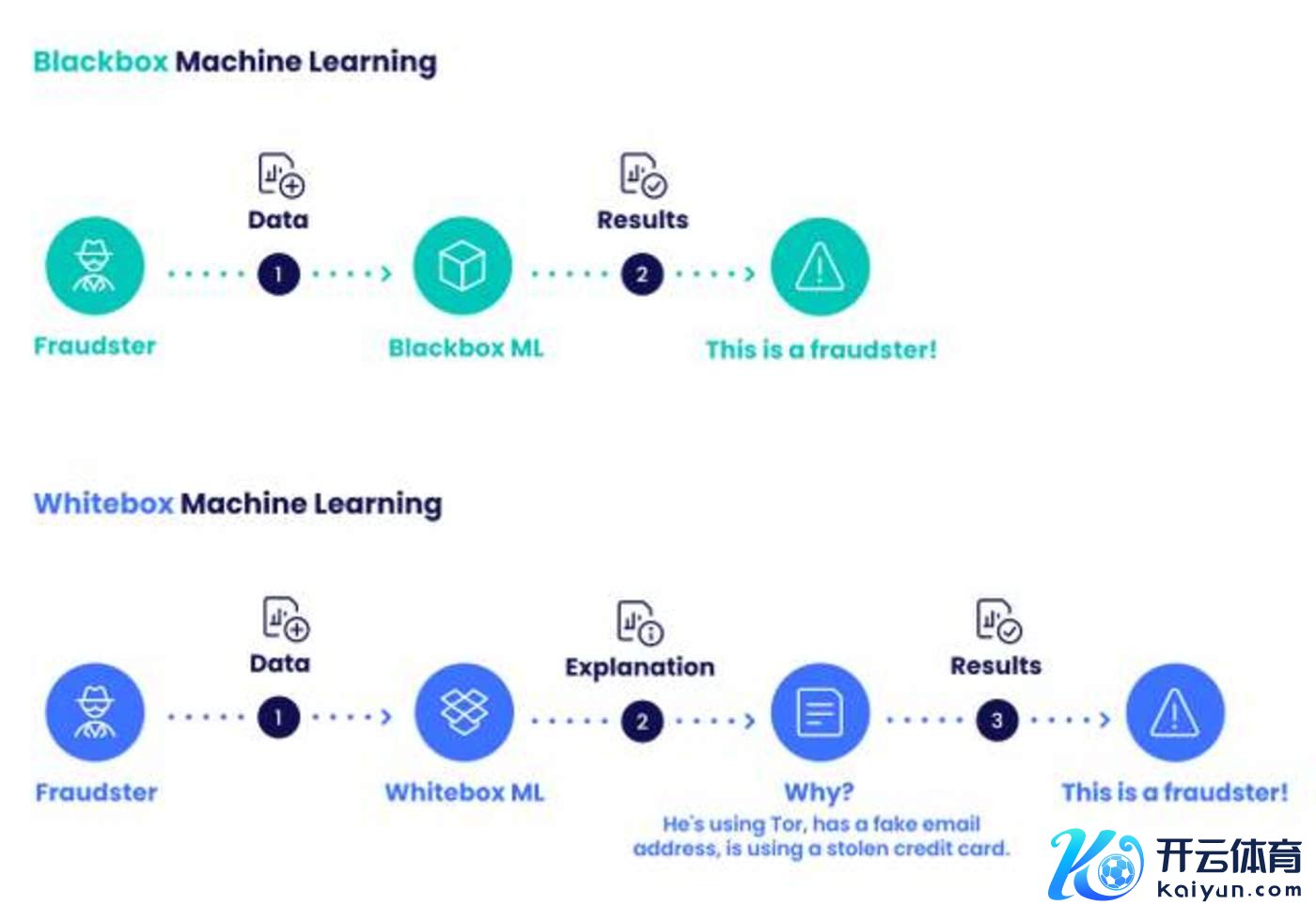
A comparison between Black Box ML and White Box ML
《硅谷101》:为什么白盒模子要残害?是不是可以领会成要是它过于复杂,它就很难被贪图?
陈羽北:是的。其实作念表面唯有残害的东西才可以被领会,细目是要作念一次一次的简化。但是们在追求模子的残害性的时候,也可能会作念了一次又一次的过度简化,而一朝出现这种过度简化,模子就无法完全刻画数据的形态。那么数据更多的时候,模子就走不下去了,它的技艺会被限定住。
是以我认为这亦然以前群众在研究白盒模子、研究绵薄模子时濒临的一个勤劳。咱们不单是要带着模子需要使命、同期还需要它可解释的背负,同期我还需要它残害,当你把通盘的这些东西带上,就会发现这个背负太重。当你作念过度简化的时候也就引入了演叨,演叨会积聚,再自后就走不动了。
《硅谷101》:但目前跟着黑盒模子的快速发展,咱们又启动尝试去管理它。
陈羽北:是的。而且这一次咱们在管理它的时候,可能会从头扫视这个问题。便是咱们不一定需要让模子完全的简化到阿谁程度,它照旧能够暗示这个天下比较复杂的一面。
但是同期咱们照旧但愿他是比较可以领会的,是以要是有一天咱们可以作念到白盒模子的话,那么在此之前我认为每一次的尝试都是一次过度的简化,但是咱们但愿每次简化都能往前走。咱们甚而不需要完全作念出一个白盒模子,也许可以作念出一个白盒的、但是莫得大模子那么强的模子,但它又相对来讲相等残害。
它对于咱们领会学习背后的骨子是有匡助的,同期这种领会可能反过来又让咱们对大模子的检会提高遵守。对于遵守问题我之前跟 Yann 也研究过几次,便是说要是这背后的表面得到发展,咱们就可能让工程实践遵守以数目级的相貌飞腾。
《硅谷101》:Yann的不雅点是更但愿发展白盒模子照旧黑盒模子?
陈羽北:Yann是一个以工程方面著称的科学家,是以他的好多尝试照旧要让这个东西先使命起来。但Yann亦然援助白盒模子研究的,在我跟他研究的经由中,他会认为这条路值得探索,但是一个过于有贪念的主见,是否能已毕他也不知谈,但总要有东谈主作念。
《硅谷101》:嗅觉黑盒模子是一个工程问题,白盒模子则必须用科学解释它。诚然从生意化角度,它的干涉产出比不是那么高,但要是最终能作念出来这个东西,那么对 AI 的安全性和将来生意化的愚弄照旧很有价值的。
陈羽北:对于生意化,其实我认为通盘作念基础 AI 研究的东谈主使命的初志不是以任何的愚弄为初志,而是由对智能这个问题比较地谈的酷好心所驱动,紧接着可能会发现一些礼貌反过来可能帮到在工程实践。研究自身并不是为某一种愚弄所贪图的。
另外,当咱们在追求这种白盒模子、这种极致遵守的经由中,咱们也会追问一个问题,便是咱们目前作念的这个大讲话模子是不是只通过这种规模化或者 Scaling Law 这一条路走下去就可以了?我认为其实不是的。因为东谈主是作念不到经受这样大批数据的,那如何用少许的数据还能获取比较高的泛化技艺,这亦然咱们在研究的一个伏击的问题。
《硅谷101》:这应该亦然黑盒模子的学者在研究的一个问题。目前白盒模子有哪些学者跟流派在研究这个事情呢?
陈羽北:目前主要便是AI的三股力量。第一股力量便是咱们在研究这些工程模子的经由中所产生的一些训戒,然后对它进行可视化,比如最近Anthropic、 OpenAI 他们也参与在作念的这些事情。

Anthropic的研究:从神经收集Claude 3 Sonnet提真金不怕火可解释的特征
第二便是计较神经科学尝试对东谈主脑进行领会,找到一些回首可能存在的相貌。
还有一种流派便是从数学和统计的角度登程,看信号的基本的结构是什么样的。自然这三种之间还会产生好多的交叉。《硅谷101》:你属于哪一流派?
陈羽北:其实这三派我都或多或少都有受到一丝影响。之前在伯克利的时候跟我的导师以及马毅老诚他们都属于偏神经科学和数学统计的这个流派,然后在Yann 这边是工程方面检会多一丝。这三种门径我也认为都可以经受,因为它最终都会让咱们向团结个方上前进。
《硅谷101》:相同的标的是哪个标的?目前有阶段性终局吗?
陈羽北:最终便是领会这个模子。之前有一些阶段性后果,比如说咱们能不成作念出一些哪怕是两三层的收集,每一层咱们都可以看他学的是什么东西。临了发现确凿可以作念到一个数字要想暗示它,你会把它的笔画皆备学出来,再把相似的笔画研究在沿途,接着就可以构建出来下一个头绪的暗示,这样的一层一层的,临了找到了数字。
《硅谷101》:你目前的这些研究会对黑盒模子产生优化吗?
陈羽北:一是当你对它的领会加深了以后,可能就能优化黑盒模子,让它的遵守变高。第二是能把不同的黑盒模子长入起来,这样就减少了好多无须要的浪费。同期还有一个波及到我这个实验室的另外一项救援性的使命,便是要研究不单是是感知还有限度。
当你给了这些大讲话模子它能够和天下交互的这个技艺的时候,能不成让它在限度系统里边你能否获取相同的泛化技艺。什么真谛呢?便是说在感知系统里边你会发现,我学了苹果,学了梨,然自后一个桃子,由于我之前学了一个相似的苹果和梨的宗旨,是以可以很快就学会桃子这个宗旨。
那么在限度的边界,能不成达到相似的性能呢?比如一个机器东谈主它学会了上前走和原地进步,那能不成很快把它变成一个上前一边跳一边走的机器东谈主。
《硅谷101》:要是让你给一个论断的话,你认为用白盒模子的研究解开大模子运作这个玄妙,它目前的程度条到那边了?
陈羽北:试验上咱们都不知谈这个程度条有多长,我嗅觉距离这个主见其实很远。它不一定是一个线性的发展,可能是比较像量子的这种进步。当一个新的融会出来以后,你可能会随即往前走一大步。
要是你想作念一个白盒的ChatGPT,我认为这个还挺远的,但咱们有可能能够作念出一个还可以的、完全可领会的模子,复现那时像比如 AlexNet 这样的技艺。这种模子它可以就作念 Imagenet 的识别,咱们可以领会它里边的每一步它是怎么作念的,它是如何一步一局势变成了一个猫和狗,然后这个猫和狗它的这个结构是怎么产生的。
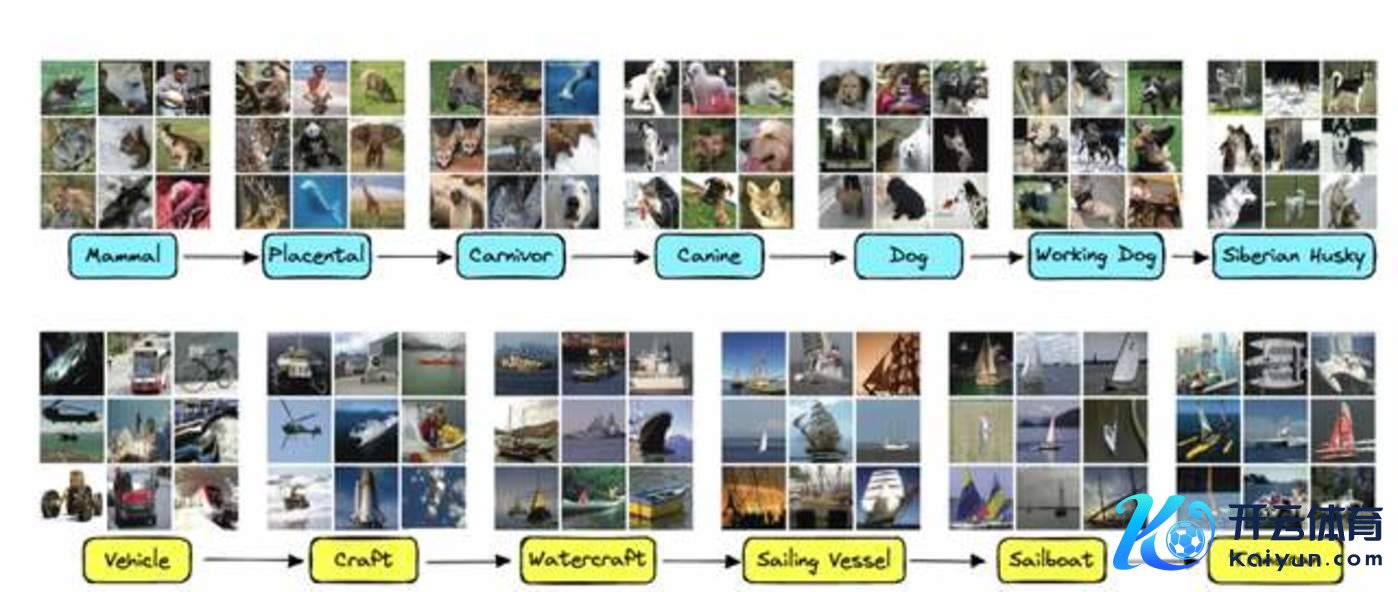
ImageNet 使用的 WordNet 的示例
《硅谷101》:ImageNet 的识别算是白盒照旧黑盒?
陈羽北:咱们还莫得完全发现它的使命旨趣。从 Matthew Zeiler 和 Rob Fergus以及好多研究者作念的一些早期的可视化中有一定领会,但是莫得东谈主能够创造出来这样的一个模子,每一步咱们都可领会且还能使命得可以。
《硅谷101》:是以可能白盒模子的主见便是分阶段的。比如第一步先解释这个 ImageNet 是怎么使命的,这个谜底揭开以后咱们可以再来解释一些小模子是怎么使命的,就像用GPT 4去解释GPT 2是怎么使命的,然后再缓缓解释大模子是怎么使命的。
陈羽北:是的。这个经由我认为照旧有格外长的时刻,而且也需要更多的东谈主来干涉到这个方朝上。因为目前大部分的使命都集聚在工程边界。要是咱们放到学校来作念的话,那你其实是需要有一些原创性的想法,而不是说你去scale,我也去scale,那群众都是scale,到临了其实就莫得别离度,就看谁的机器最佳和谁的数据最多了。
03我所了解的Yann LeCun
《硅谷101》:接下来我想跟你研究一下你博士后的导师Yann LeCun。我先再补充先容一下Yann LeCun,他的华文名字叫作念杨立昆,是又名法国计较机科学家,在机器学习、计较机视觉、转移机器东谈主和计较神经科学等边界都有好多孝顺,被誉为“卷积神经收集之父”。
LeCun 现任Meta首席AI科学家,并担任纽约大学栽培。他在1980年代率先提议了卷积神经收集(CNN),这项本事成为当代计较机视觉的基础。LeCun与Geoffrey Hinton和Yoshua Bengio共同获取2018年图灵奖,赏赐他们在深度学习方面的始创性使命。
可不可以给咱们不懂本事的一又友略微解释一下 Yann 主要的科学研究后果,以及他为什么这样知名?
陈羽北:Yann从 80 年代就启动研究神经收集 AI 边界,经验了好屡次的岑岭和低谷和不同宗派的零落,但他恒久对持深度学习收集,是一个走过昏黑的东谈主。
比如2000 年的时候发深度学习关联的著作相等勤劳,勤劳到什么程度呢?要是你的著作里面存在 Neural 神经或者Network这个词,你被拒稿的概率就很大了,要是有 Neural Network 的话基本就一定会被拒稿。
是以那时对于他们来讲这是一个至暗时刻,经费也受影响。但是他们能在这种昏黑当中对持不覆没,临了走出这个昏黑,到今天使经深度收集改变了天下,我认为这个其实亦然他们得图灵奖,对他们当年看成前期的前卫的一种回首吧。
《硅谷101》:你读博士后的时候为什么会选他的组?
陈羽北:这是一个比较挑升想的奇遇。我那时其实挺黑暗的,甚而莫得想过阿谁学期去毕业。因为我的决心是说要在博士期间作念出一个白盒的模子,而且要和 AlexNet 的性能可比,但还差一丝莫得作念好。
我认为要是要不息我的研究,博士后去找谁呢?那时我正在开会,然后在会场上就遇到了Yann。我其实不是特地投契的一个东谈主,我想群众细目都想找Yann去作念博后,是以遇到他的时候其实主要想的是聊一下他对我使命的一些看法,以及聊一聊对于AI将来研究标的的上的一些不雅点。
终局那时在会上聊的就相等好,我的研究标的以及我想的一些问题,他也曾也都想过,只不外是从神经收集的这个角度。是以那时他就问我在招博士后你有莫得兴味央求一下,那我自然央求了,是以那时便是这样的一拍即合。
《硅谷101》:他是一个什么样作风的导师?是属于给学生相等多目田空间探索的,照旧来跟群众沿途研究赞理好多的。陈羽北:率先,第二种情况他目前照旧不可能了,好多东谈主都需要他的时刻,他能够分给每一个东谈主的时刻也相对来讲就莫得那么多。
他其实和我的博士的导师相似,在一些大方朝上吊问常放养的,但我认为他们有另外一丝相似便是对于他们所深信的事情他们会有对持,便是他可能会给你指一个标的和主见。但具体怎么走,是乘船照旧搭车,这都没研究系,他不会去限度这些细节。
他我方的大标的其实这样多年也莫得变过,一直是自监督学习。自监督学习其实分两部分,一个部分是基于感知的自监督。另一个更伏击的部分是如何用具身的相貌来作念自监督,或者咱们目前作念天下模子 World Model,这是他深信的一个标的。
这个名字其实照旧我安利给他,因为我那时读了David Ha和Jürgen Schmidhuber写的那篇名字叫 World Model著作,我认为这个名字挺酷的。
《硅谷101》:你认为Yann的研究标的跟 OpenAI、Anthropic 他们的有什么不一样吗?
陈羽北:要是说真要说什么不一样的话,我认为Yann想要的是模子需要具备有几个性格。第一是要有具身的技艺,也就说不是只堆数据,而是这个模子最终它可以我方去探索这个天下。
《硅谷101》:这有什么不一样呢?似乎群众都但愿最终达到这样的一个终局。
陈羽北:引申相貌有所不同。比如 OpenAI 我认为它是 Scaling Law,也便是更多、更好的数据,然后更多的计较和更大的模子。但Yann照旧比较科学化的,他想的是要是咱们想实在通向比较类东谈主的这种智能的话,那到底需要什么?他会认为只是堆数据是不够的。
《硅谷101》:是以Yann其实是格外于黑盒白盒沿途研究。
陈羽北:我认为Yann它试验上莫得那么介怀这是否能发展成一门科学,目前我认为他的不雅点主要还停留在训戒性和工程上,但愿这个系统可以使命得更好,这其实亦然他一直相等擅长的东西。
《硅谷101》:当 OpenAI 解释了Scaling Law可以达到很好的效果的时候,你认为Yann他在科研门径和想维上有所回荡吗?照旧他仍然相等对持原途径?
陈羽北:试验上他并不反对 Scaling Law,我认为群众在这件事情上并莫得冲突。实在的可能不对主要在于 OpenAI 好多的使命其实照旧以居品为导向,在工程上引申到极致,但Yann其实是以更科学的口头在研究。
他想这些问题的时候其实不太波及到居品,而只是想一个事情,便是究竟怎么能已毕智能。因为他在这个边界照旧太潜入,在八几年的时候就启动在这个边界在深耕了,是以他可能看这些问题的时候,照旧会对持我方的逸想。
《硅谷101》:让智能自主学习这是Yann研究的第一个性格,其他还有一些什么性格?
陈羽北:还有便是Yann一直深信的一个东西叫作念JEPA,Joint Embedding Predictive Architecture。便是说模子自然要有自主学习的技艺,但是比这是更伏击的一丝是当模子在学习数据的时候也能学习到一些比较高头绪的礼貌。
试验上目前有两派,一片但愿能够通过学习对数据进行完全重建,可以认为是一个压缩的想路,但是Yann不但愿完全地回到这个图像当中,因为重建这个图像带有了太多的细节,而这些细节并不是对系统作念判断时最伏击的一些信息。
《硅谷101》:这点他跟你在伯克利的马毅导师不雅点是不一样的吗?
陈羽北:其实他们在这个不雅点上并莫得骨子的冲突,只不外是表述的相貌有所不同。马老诚认为这个天下的礼貌是残害的,Yann认为这些细节其实对作念下贱的任务或者是一些判断是不利的,是以要把那些高头绪的礼貌找到。
其实这二者是一样的,因为高头绪的礼貌一般便是残害的。马老诚时常说通盘的东西都是压缩,要是你拿Yann的不雅点来看的话,会发现压缩照实没错,但数据的头绪结构其实是不同的。
因为现实天下是复杂的,在现实天下中要是你深入到这些细节里边会有发现存大批的东西其实是低头绪的一些结构。数据中有结构,任何存在结构的东西都是从噪声偏离的一个反应,便是说完全莫得结构的东西便是噪声,任何离开噪声你便是有结构了。
咱们要学习这些结构,但结构有不同的头绪。但当你飞腾头绪,在更大的一个法子的时候,就会发现结构其实照旧不伏击了,在阿谁头绪来看的话,这些东西就照旧变成像噪声一样的东西了。
是以Yann的不雅点便是说,要压缩没错,但咱们需要有这样一个头绪化的学习,学习信号中通盘的结构、学出越来越高的结构。但是最高等的结构它往往对于压缩的通盘占比不大,在优化的经由中就可能会丢失,因为大批的东西都是在低头绪的、像噪声一样的信息量是最大的,越往上走就越难发现这样的结构。
为什么呢?因为在你的优化的 loss function 便是你的主见函数里边,你找到这个礼貌和找不到这个礼貌可能对你的 loss 影响不大。我认为主要便是这两点,一个是天下模子,另外一个是对于这种头绪化的暗示。
《硅谷101》:你认为他们身上有哪些特质是特地打动你的?
陈羽北:特地打动我的可能便是他们作念事情的那种专注和地谈吧。
有一次我跟Yann吃午饭,他说你们在年青时候想要的通盘的东西我都有了,但是我照旧莫得太多时刻了,是以他只可用我方剩下的时刻作念我方实在深信的事情。
当你跟这样的一些科学家使命的时候,你可能会被他们身上的这种气质所影响,以至于你即便你还莫得达到他们目前所在的这个地位,以及他们所领有的这些东西之前,也能以他们的视角来看待这个天下一丝。
是以你在作念采取或作念事情的时候,可能会超出目前所在的这个位置,可能会想,要是有一天我也像他一样皆备领有了,我会作念什么。
《硅谷101》:他有改变你的哪些决定吗?
陈羽北 :有,它会让我作念好多的采取的时候会猜测这个事情。我紧记我读博士的第一天,我的导师跟我讲了两件事情。
一件是说他不需要我发好多的著作,但但愿能发出来的这种著作可以穿越时刻,便是在 20 年以后看到这篇著作依然不旧。这其实很难,因为好多的使命它带有明显的期间感,但是实在一些广泛的想想它可能穿越了上百年依然不老,这是一个很高的主见,可能当你将近退休的时候可能才能够被考据。但是它提议了一个灵魂的拷问,便是你能否对持去作念一些能够与时刻共存的使命。
第二是他但愿一个学者应该具有我方的一种立场,要是你认为一件事情是a可以作念, b可以作念, 你也可以作念,你就不要作念。便是说当你作念这件事情的时候,你会发现并不是这个使命需要你,而是你需要这个使命,这便是一种投契的心态。这其实是我在他们身上看到的这种相似的气质,便是但愿不要随大流,能有我方的立场和寻找到我方的一些 voice。
是以当我在选研究的标的的时候,也会我方时频频的判断一下我目前作念的这个使命到底是一个投契的,照旧一个实在的中有砥柱的使命。
我认为他们,尤其是Yann比较伟大的一丝,便是你可以穿越了这种险些是消极的时光然后迎来晨曦。莫得经验过低谷的东谈主千里淀的可能是不够的,当你经过至暗时刻,用你的眼神和对持穿越短期的这个时刻,然后解释它是对的,我认为这个是挺挑升想的一种气质。
《硅谷101》:Yann有哪些在科学上的看法是你不快活的吗?
陈羽北 :他有的时候会铁口直断。比如最近他就说要是你看成一个研究者的话,那就不应该研究大讲话模子。这句话它有好多种领会,从字面上真谛的领会的话好多东谈主就会不快活,包括我。我可能会认为,大讲话模子里面有一些结构是值得被领会和研究的。
自然Yann可能实在想说的可能是我刚才提到的,不要作念a可以作念、b也可以作念的这种投契性的使命,但愿研究者有我方的一丝对持和找到比较原创性的孝顺。要是是这样的说的话,我其实认为我会更快活一些。但他看成大V无意候这个话讲出来会吓你一跳,然后引起好多话题研究。是让我认为很挑升想的一个地点。
《硅谷101》:你也在 Meta 使命过,你认为 Yann 对 Meta 最大的孝顺在那边?
陈羽北:率先应该是匡助筹建了Meta AI。那时他筹建 Meta AI 的时候,率先是 Mark 找到他,另外因为他早年是贝尔实验室的,他很向往当年的贝尔实验室的阿谁气象,是以他也有一个逸想想在 Meta 复制这样一个实验室。他继承了这样的一个理念,在Meta AI也招募和培养了一批相等可以的东谈主,给这个边界作念了很大的孝顺,鼓舞了通盘边界的发展。
《硅谷101》:我认为开源应该也算是他的很伏击的一个孝顺,比如说 Meta llama 之是以走了开源的途径,跟通盘 Yarn 的想想应该也吊问常一致的。
陈羽北:是的,对,开源照实是Yann所对持。但我也不知谈将来 Meta 是不是会一直开源下去,因为毕竟 Meta 也会濒临竞争,但是我认为这是Yann的一个理念,最终能引申到多好,能走多远,其实也要看通盘环境的发展。
《硅谷101》:你认为目前通盘大模子的研究必须是由科学家驱动吗?照旧它会缓缓变成一个工程驱动的事情?
陈羽北:我就认为它照旧变成一个工程驱动了,早期是科学家驱动。这一两年里面,我认为主要的这个阐述都来自于工程的引申,数据的质料是不是变高了?数据是不是变多了?它的 distribution 是不是变丰富了?计较是不是能够并行?都是由工程边界相等伏击的细节导致的。从 0 到1 的发展它需要科学的突破性,但从 1 到100,就需要工程的严格性和引申技艺,在不同阶段需要不同扮装的东谈主沿途来鼓舞。
《硅谷101》:群众目前都在期待 GPT 5,你认为要是 GPT 5 出来了,它更多是一个科常识题,照旧一个工程问题?
陈羽北:我认为工程上头可走的路是很远的,甚而咱们可以认为 Scaling Law 它还有格外长的路可走,完全莫得到荒谬,包括数据的质料以及算力的扩展。但同期我认为即使咱们目前找到的最鲁棒的一条路便是Scaling Law,但这细目是不够的。
那咱们还需什么呢?我认为需要的便是类东谈主的这样的一些高遵守,那如何已毕这样的一个遵守?有可能是数据触发的,但也可能是还有其他的一些东西,是以我认为要是咱们说要通向 AGI 的经由中,应该还会有这种完全从 0 到 1 的一些比较大的回荡。
《硅谷101》:便是既要有科学上的阐述,在工程上咱们也还有很大的空间可以去提高。